![[FP]淺談functional programming效率優化](http://mis101bird.github.io/images/leak.jpg)
程式效率是常被人忽略的魔鬼
We should forget about small efficiencies, say about 97% of the time… premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.
– Donald Knuth, The Art of Computer Programming
如果對 functional programming 的 coding 方式有所了解,就會知道它利用 function 去抽象化資料的操作,以語意隱藏每個步驟的實作細節,讓程式碼可讀性更高,更容易用 pipeline 的方式對資料流作分析。
但程式的 效率 和 抽象化(abstraction) 通常無法兩者兼得,像是 functional programming 最常用的 currying, recursion 等等…肯定沒有直接用 for, iterative 來的有效率,還要注意 stack overflow 等問題,但 functional programming 的編程方式有利於一些效率優化的策略,且效果顯著,本文會針對這些策略做說明。
- 解說 context stack 和 javascript function 的原理
- 三個優化方法
- lazy evaluation 延遲執行
- memorization 記憶法
- recursive call optimization 尾遞歸
Context Stack 和 Javascript Function
當 JavaScript 呼叫 function 時,會在內部創建一個紀錄目前 Function 執行環境的物件 (Execution Context frame) 並放入 Function context stack。Function context stack 被 Javascript 設計用來儲存這些Execution Context frame,記錄整個程式執行的狀況。
當程式一啟動,Global Context frame 會與 Function context stack 一起生成,放在 Stack 最底端,儲存著程式的全局變數。

每一次呼叫 function 都會在 context stack 產生新的 Execution Context frame,最前方的 context frame 叫做 active context,是目前 code 的執行環境。在 code 執行完成後,active context 會被移出 stack,換下一個最前方的 context 當 active context,以下圖為例就是 logger。
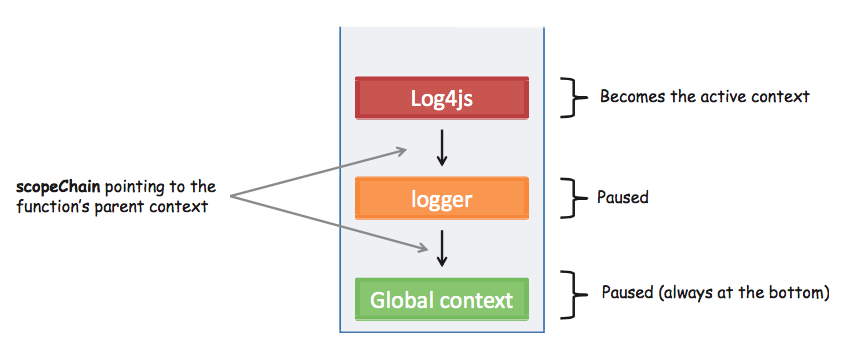
程式碼對照
const logger = function (arguments){
var Log = new Log4js.getLogger(arguments)
...
}以下用一個錯誤的 recursive code 為例子,來測試瀏覽器到達 Range Error: Maximum Call Stack Exceeded 的情況。不同瀏覽器能接受的 frame 數量不同,我用 Google Chrome v57.0 測試,發現可以接受約16035個。示意圖如下。
function longest(i) {
console.log(i);
longest(++i);
}
longest(1);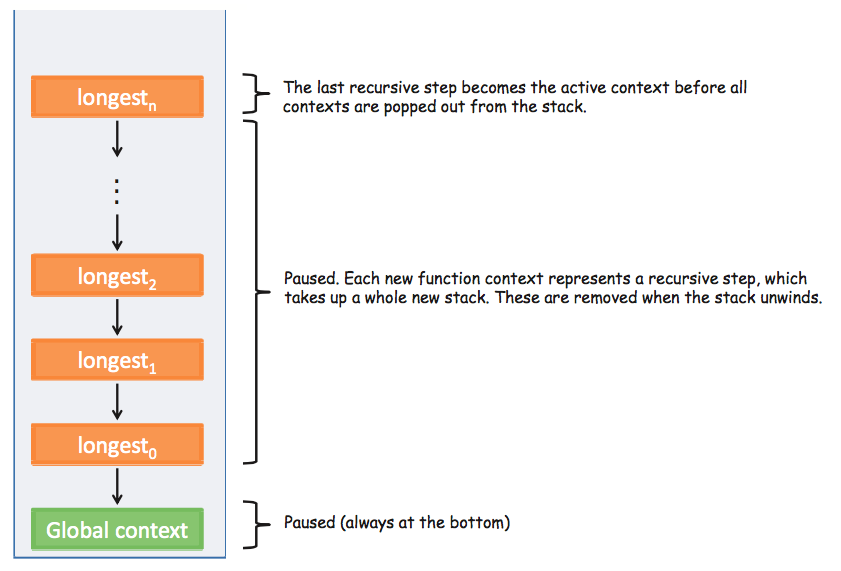
Lazy Evaluation
延遲調用 (Lazy Evaluation) 的精髓在於,將需要做的操作事先宣告好,相依資料都準備齊全,在真正需要執行的地方才執行操作。這樣做的好處是只針對必要的資料做計算,不用浪費時間計算不需要用到的資料。如下圖,主流的 Javascript coding 方式是 eager evaluation,資料會在需要用到之前就全部準備好,這種做法會因為浪費無謂的計算時間,而降低程式效率,相比下來,Lazy Evaluation 就只會計算需要用到的資料。
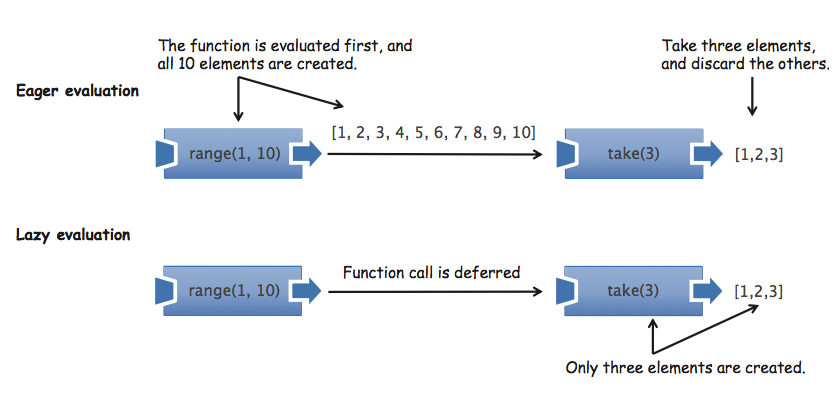
下面再進一步講解 Lazy Evaluation 帶給我們的兩個優點:
- Avoiding needless computations 避免不必要的計算
- Using shortcut fusion in functional libraries 使用“融合操作”提升效率
關於”避免不必要的計算”,下面給了一個簡單的例子,將 alt 與 append 兩個 Function 做”事先”組合,在 showStudent 指定的學生學號 (val) 輸入時,才執行 func1, func2 和 append。
// R為Ramda
const alt = R.curry((func1, func2, val) => func1(val) || func2(val));
const showStudent = R.compose(append('#student-info'), alt(findStudent, createNewStudent));
showStudent('444-44-4444');這種”後執行”的模式,也得利於資料暫存,甚至能在執行時,根據輸入的資料,對一連串 pipeline 步驟做優化,我們叫它 shortcut fusion。很多 functional libraries 已經幫我們實現這種優化,以 Lodash 的 _.chain 為例子,他不只可以將一系列的 function 串起來,並在該執行的時候利用 value() 執行;還可以整合 function 的執行與暫存,使其更有效率,舉例如下。
const square = (x) => Math.pow(x, 2); // 平方
const isEven = (x) => x % 2 === 0; // 是否偶數
const numbers = _.range(200);
const result =
_.chain(numbers)
.map(square)
.filter(isEven)
.take(3) // 取前三的偶數值
.value(); //-> [0,4,16]
result.length; //-> 5我們可以發現結果 result 的容器長度只有 5,代表 Lodash 只計算了5個數值就完成了本操作的計算。對比計算全部 200 個數字才取前三個數值回傳,效率快了不少。
關於優化方法,首先 take(3) 讓 Lodash 知道本操作,只需要取前三個通過 map 和 filter 的數值即可;再來 Lodash 運用 shortcut fusion,將 map 和 filter 操作合併 compose(filter(isEven), map(square)),如此每個數值就不需要等其他數值計算完 map 才執行 filter,而是會一次性的經過平方和偶數判斷,由此省下不必要的計算時間。如果我們在 square 和 isEven 放 console.log,如下。
square = R.compose(R.tap(() => trace('Mapping')), square);
isEven= R.compose(R.tap(() => trace('then filtering')), isEven);我們會觀察到 console 會 print 出以下的訊息五遍:
Mapping
then filteringMemoization 記憶法
使用暫存 (cache) 是增加效率很重要的一種做法,而 functional programming 可以將 Memoization 運用到一個極致。
Cache 的實作方式,簡單說如下。在執行費時操作前,先檢查 cache 內是否有相對應的解答,如果沒有才做計算。
Memoization 要對擁有 referential transparency 特性的 function 才適合,因為其回傳值的影響因子只有函式參數,沒有 side effect 干擾,而函數參數正能當 Cache 裡 key-value pair 中的 key。
function cachedFn (cache, fn, args) {
let key = fn.name + JSON.stringify(args);
if(contains(cache, key)) { // 檢查是否暫存有相對應的解答
return get(cache, key); // 回傳暫存的結果
} else {
let result = fn.apply(this, args); // 執行費時操作
put(cache, key, result);
return result;
}
}我們可以用 cachedFu 來裝飾 findStudent,讓他擁有暫存的功能!如下。
var cache = {};
cachedFn(cache, findStudent, '444-44-4444');
cachedFn(cache, findStudent, '444-44-4444'); // 第二次取暫存的數值,執行速度超快這種架構類似於 Design pattern 中的 proxy pattern,由 cachedFn 代理 findStudent,在執行 findStudent 前確認是否 cache 已經存有相應的結果;在執行findStudent 後,將回傳的結果儲存進 cache。但這種寫法,cache 和 function 是分離的,不只測試麻煩,還需要花額外邏輯去管理不同 function 的 cache。下面再介紹更進階的做法。
在 Function 中內建 cache
// 將cache儲存在Function的prototype
Function.prototype.memoized = function () {
let key = JSON.stringify(arguments);
this._cache = this._cache || {}; // 產生內部的 cache
this._cache[key] = this._cache[key] || this.apply(this, arguments); // 如果cache的 key-value pair不存在,則執行此耗時操作
return this._cache[key];
};
Function.prototype.memoize = function () {
let fn = this;
if (fn.length === 0 || fn.length > 1) { // 只讓擁有一個參數的function擁有cache
return fn;
}
return function () {
return fn.memoized.apply(fn, arguments);
};
};用這種方式將 cache 裝在各自的函式內部,避免創建 Global shared cache 而污染 Global Context,又方便做測試。我們用以下的 code sample 做展示。
var rot13 = s =>
s.replace(/[a-zA-Z]/g, c => String.fromCharCode((c <= 'Z' ? 90 : 122) >= (c = c.charCodeAt(0) + 13) ? c : c - 26));var rot13 = rot13.memoize(); // 使用cache觀察後發現,第二次呼叫的時間比第一次呼叫的時間快約 0.7 ms!
rot13('functional_js_50_off'); // 0.733 ms
rot13('functional_js_50_off'); // second time: 0.021 ms他們之間的交互作用如下:
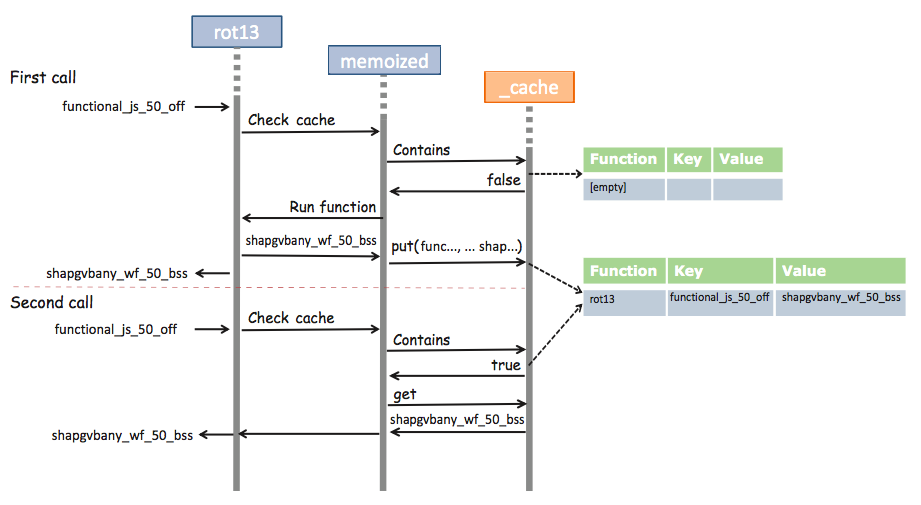
Functional Programming 有利於 Memoization
以化學中的溶解度為例,粉狀的溶質比塊狀的溶質更容易溶解於溶劑,是因為粉狀的溶質接觸的表面積比較大;同樣的,當我們將 function 的步驟切的越細,耦合度越低,Cache 就能做的越仔細,也就能在各種微小的地方節省時間,進而產生很大的效能進步。舉一個例子
const m_cleanInput = cleanInput.memoize(); // 輸入做暫存
const m_checkLengthSsn = checkLengthSsn.memoize(); // 檢查結果做暫存
const m_findStudent = findStudent.memoize(); // 學生結果做暫存
const showStudent = R.compose(
map(append('#student-info')),
liftIO,
chain(csv),
map(R.props(['ssn', 'firstname', 'lastname'])),
map(m_findStudent),
map(m_checkLengthSsn),
lift(m_cleanInput));showStudent('444-44-4444').run(); //-> 9.2 ms on average (no memoization)
showStudent('444-44-4444').run(); //-> 2.5 ms on average (with memoization)由上可知,每個微小的步驟都做暫存,累積起來後,在效能方面會有很大的改善。
遞迴和尾遞迴 (tail-call optimization (TCO))
由上一節,我們已經知道要使用 Memoization,Function 必須要是 referential transparency 且參數重複的可能性大,才有做 cache 的意義。但有的 Function 參數重複的機率低,又超乎想像的耗時,又使用大量 recursive,有什麼方法能讓 recursive 變得跟 loop 一樣有效率呢? 答案是,將 recursive 寫成尾遞迴 (tail-call optimization (TCO)) 的形式。
TCO
尾遞迴如下,將遞迴的 Function 放在函式最尾端,作為最晚執行的部分。
const factorial = (n, current = 1) =>
(n === 1) ? current : factorial(n - 1, n * current);在經過 ES6 compiler 的最佳化後,會跟下面的 loop 一樣快!
var factorial = function (n) {
let result = 1;
for(let x = n; x > 1; x--) {
result *= x;
}
return result;
}因為尾遞迴的寫法,讓 Javascript 知道它在執行 sub factorial 時,不需要將目前的 frame 保留,因為 sub factorial 執行完後不需要回到 parent context 去做剩下的工作。所以他可以在執行 sub factorial 前就直接將目前的 Active context 給丟棄,並將 sub factorial 的 Context frame 變成新的 Active frame。這種做法不只加快效率,也避免了可能 Stack Overflow 等問題。
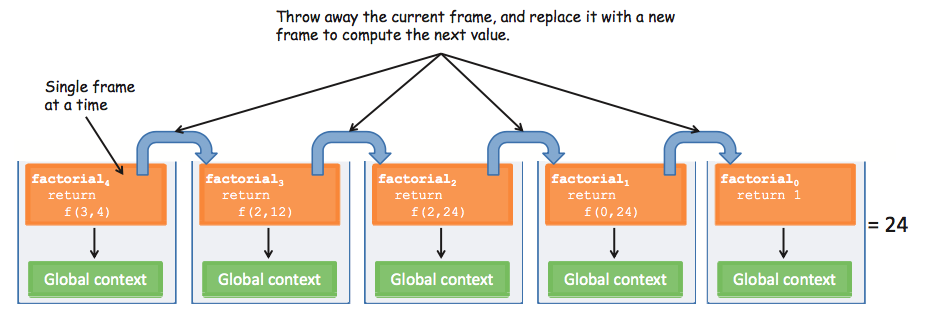
如何將遞迴寫成尾遞迴?
首先,來一個不是尾遞迴的函式。
const factorial = (n) =>
(n === 1) ? 1 : (n * factorial(n - 1));他不是尾遞迴的原因,是因為在 factorial(n - 1) 執行完後,還需要回到原本呼叫 factorial(n - 1) 的父函式,進行乘 n 的動作。如果要將它轉成尾遞迴,必須依照下面步驟:
- 將乘法操作當成 current 參數傳入 factorial
- 使用 ES6 default parameters 的特性,為每個參數設定初始值
改寫的結果為:
const factorial = (n, current = 1) =>
(n === 1) ? current : factorial(n - 1, n * current);下面有比較,比對 TCO 和 iterative 是多麼地相似,但 TCO 可讀性又比 iterative 更高一些。
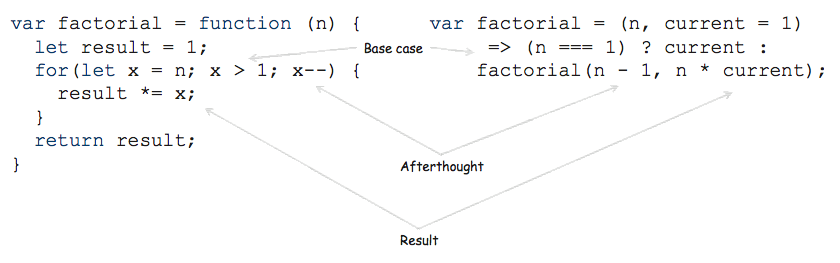
再來一個範例,請將下面的 recursive function 改成 TCO
function sum(arr) {
if(_.isEmpty(arr)) {
return 0;
}
return _.first(arr) + sum(_.rest(arr));
}一樣遵照上面兩個步驟,先將 function 尾部需要做的事情移成 function 的新參數,再設定參數的 default value,改寫結果如下。
function sum(arr, acc = 0) {
if(_.isEmpty(arr)) {
return 0;
}
return sum(_.rest(arr), acc + _.first(arr));
}在團隊合作中,有時程式的可讀性比程式效率本身來得重要,尤其是在這個電腦運算已經如此快速的年代,也因此,最近 functional programming 的撰寫方式才會流行起來。究竟要使用什麼 coding 方式去實作功能,還是取決在於不同的專案和團隊需求。
總結
- Functional Programing 在某些狀況,效率會比 loop 寫法 (imperative code) 來得慢。
- 使用 functional libraties,像是 Lodash 來達成 lazy evaluation 和 shortcut fusion 等效率優化
- 使用暫存的方式 (Memoization) 來避免重複計算
- Functional programming 的低耦合,將 Memoization 發揮到極致
- 用尾遞迴 (TCO) 優化 recursive
參考與圖片來源
- 更多關於 functional programming 的奧妙都能參考此書!本篇只是我在閱讀本書其中一章的小記。
- Functional Programming in JavaScript – LUIS ATENCIO