Bill 是無極限零件公司的一名 IT 經理,有天忽然被 CEO 抓來負責這個可能讓公司起死回生的計畫:鳳凰計畫。
在本書的第一章,Bill 帶讀者經歷了每個傳統公司的 IT 部門都會遇到的困境,像是員工不遵守制度、部門工作集中於一位員工、tasks 雜亂無章難以追蹤等等…在 Bill 接近崩潰之時,一位來自董事會的成員,用工廠生產線作為比喻,引導 Bill 將 DevOps 的原則逐漸導入他的 IT 團隊,讓團隊漸入佳境。其中讓我印象最深刻的,是 SOX-404 外部稽核會議裡,公司用下游人工審查 cover 掉 IT 控制問題,本書在這裏帶入了『第一工作法』,告訴我們要時刻注意自己的任務是否和公司的大目標一致!這樣才不會花費大量時間在對公司沒有幫助的事情上。
第二章節,高層不理解 Bill,不但沒有支持 Bill 的改革計劃,還拼命施加壓力給 Bill,終於 Bill 憤而離職,讓整個公司從高處墜落,再從谷底浴火重生,印證『大破才能大興』這個諺語。第一章比爾帶讀者領悟了『四種工作類型』和『第一工作法』,第二章他們用約翰的逆襲帶入『第二工作法』,藉由到處訪問各部門的主管收集需求,開發新功能,再建立能正確把使用者感想傳達回開發端的回饋循環機制。之後為了加速這樣的循環,他們更搭配了自動化,發展出著名的『持續整合』和『持續交付』。公司每個部門的頭,性格都非常鮮明有趣,他們的轉變也令人興奮!
公司業務和 IT 之間的關係圖很重要,每個 IT 員工都要知道自己的工作和公司業務之間的關係,這樣不只激發向心力,在算績效時也比較多東西能說嘴。很多較大的公司,員工每季都要寫公司目標、個人目標,和自己在上一季對公司目標的貢獻,提醒每個人做的事情有沒有時時刻刻符合公司利益。
不管是什麼公司,其實都能稱作 IT 公司,因為沒有成功的 IT 就沒有成功的業務。只有強大的 IT,才能快速交付產品,並調整公司本身以應付市場環境的變化。舉例,像世界第一大藥廠輝瑞的產品,雖然不是最強的,但他的執行團隊就像訓練有素的軍人般執行上頭的銷售策略,能以最快最有效率的方式將藥品銷售到全世界,賺到最多利潤!輝瑞經常代理其他公司的藥品,靠該藥品賺取大把利潤後,再將該藥品的公司併購,壯大自己!
使用大家習慣的東西做任務追蹤
在主角改革前,開發部主管已經花了大筆錢建立了任務追蹤系統,嘗試要每個員工用該系統做紀錄,但大家不習慣每件事都要填一堆繁瑣的表格,最後這項政策也就無聲無息了。主角很聰明的把大家找來,要他們用最熟悉的便利貼做紀錄,在每天開會時交上便利貼,慢慢大家才習慣這種工作模式。我認為這也是 Scrum 課程喜歡從便利貼開始的原因,因為老外習慣用便利貼,一個便利貼就是一個任務,照著 TODO –> DOING –> DONE 的流程去追蹤每份工作。這裡重點在於用大家熟悉的工具去引入新的工作模式,像假設公司大多數人是習慣用 Email 的,最好做一個系統,當員工發 Email 給 IT 部門時,系統就自動產生對應的 Ticket 排到工作列中。
在應付 SOX-404 外部稽核時,其實約翰應該善用會計部門的審查小組直接對公司的敏感資料做把關,讓 IT 能在當時 Focus 在更重要的事,而不是像初期為了快速解決 IT 控制問題而上機器偷改程式碼,導致機器重新部署時錯誤連連,給主角帶來一堆隱藏性的炸彈!
布侖特告密,論下屬溝通的重要性
在系統發生意外時,主角組織應變小組去解決問題,無法解決才去拜託約束點:布倫特,這目的是為了讓 IT 部門慢慢脫離約束點的掌控,但我覺得本書的主角沒有好好跟布侖特說明他的用意,導致布侖特對於自己好像被架空感到不安,就越級上報 CEO,CEO 就以為主角亂搞而指責主角的改革計劃。下屬是否有向心力,對整個計畫是否能更有效的進行,有很大的影響,就算邊摸著石頭邊過河,也要讓下面執行的人知道目前上面的策略,降低其他變因而造成失敗的機率。
不管什麼鉅細彌遺的計畫,都比不上日常的回饋改善
執行多年的鳳凰計畫沒有結果,一直是 Work In Progress,多年過去後,當時的評估也可能因為過時,上線後仍然以失敗收場。主角對直面客戶的部門主管們,做了一系列訪談,發現他花了整本書 2/3 頁數所努力的鳳凰計畫,其實是個過時、注定會失敗的垃圾專案,但全公司的未來依然賭在這個註定失敗的專案,讓他感到十分恐惶。
主角透過訪談收集需求,歸納出其中 IT 部門能幫忙的地方 (IT 造成的業務風險/IT 加強業務理解客戶需求的精確度…),在新功能上線後,要求業務收集使用者反饋,並快速回饋給 IT 部門,這才是最棒的鳳凰計畫!也就是第二工作法!
而要達到即時反饋必須要有自動化的 CI/CD 才行,如果人工一定 2 ~ 3 週跑不掉,不能像多個採用 CI / CD 的公司 (Amazon / Facebook…) 那樣每日部署 10 幾次。所以不是 DevOps 一定要有 CI / CD,而是如果沒有 CI / CD 就做不到 DevOps,我把 DevOps 的精髓在於新的管理思維!
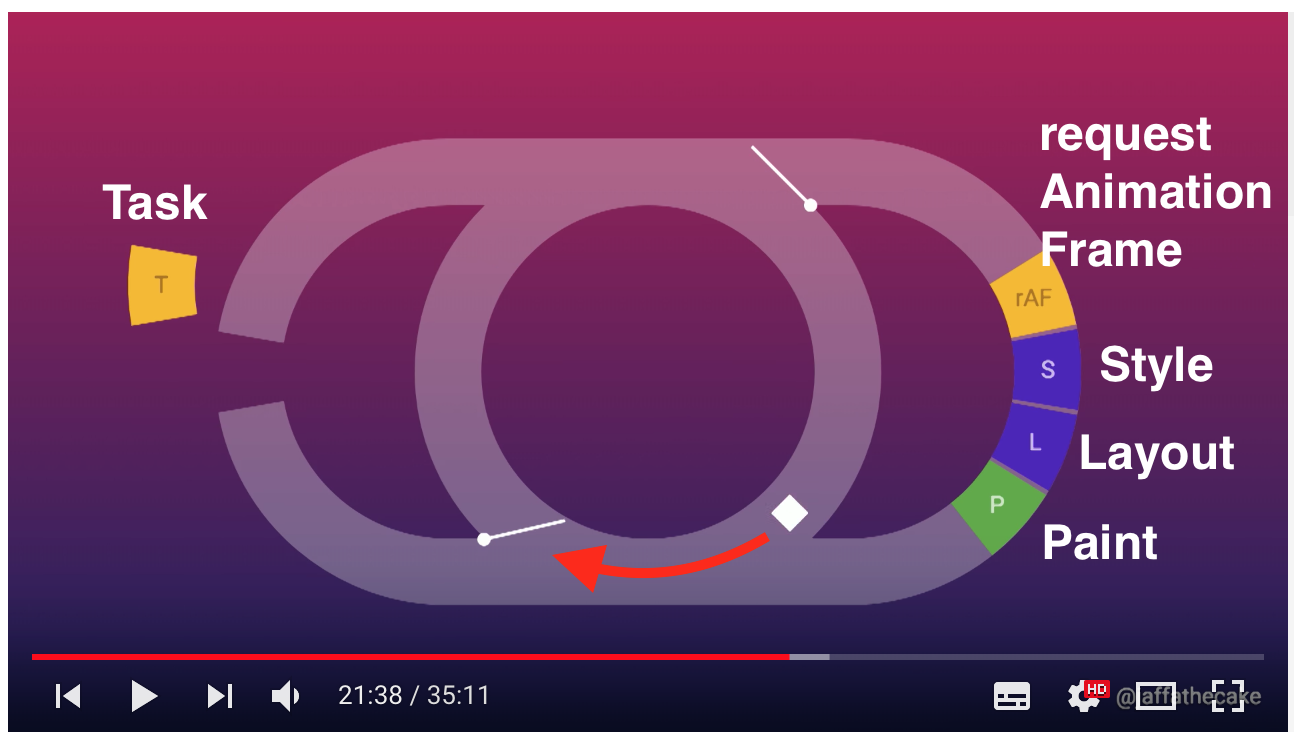
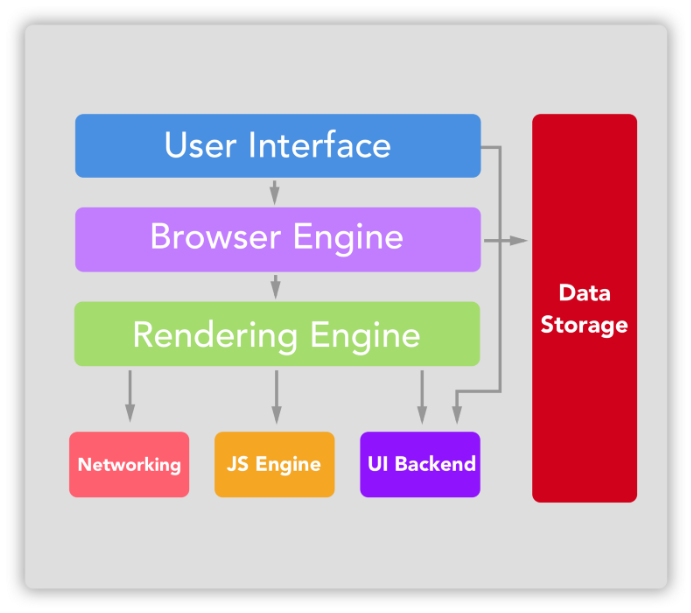
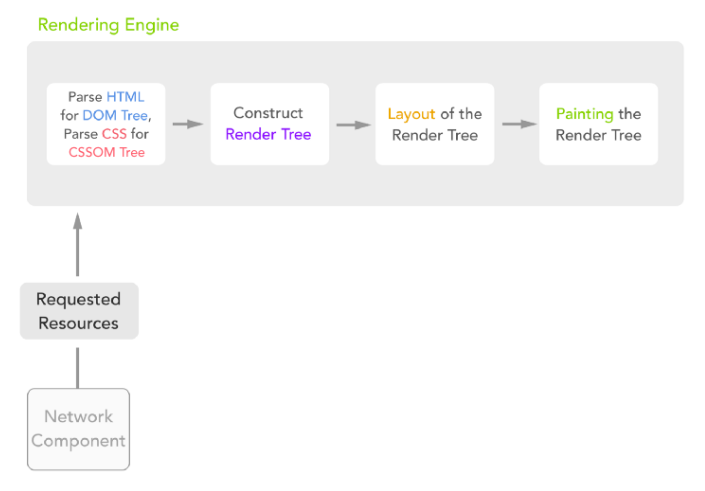
DOM 和 CSSDOM 會被拿來建構 Render Tree,瀏覽器會根據 Render Tree 執行三段過程: Layout (版面佈局) –> Paint (繪製內容) –> Composite (圖層合併) 來完成 Frame 的繪製,如下圖。
這裡要特別提到 CSS 和 JS 的阻塞特性:
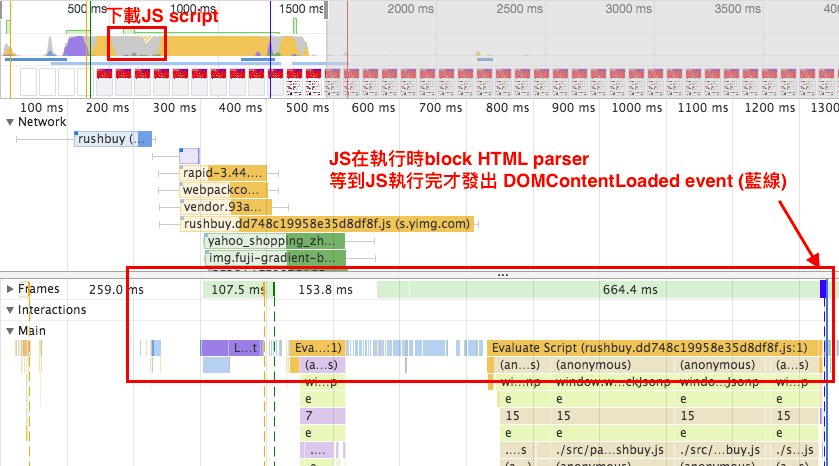
Javascript - parser blocking:當執行 JS 時,HTML / CSS 都會停止解析直到 JS 完成。其原因是 JS 擁有改變 HTML / CSS 的能力,故瀏覽器被設計成等待 JS 執行完後再繼續解析 HTML / CSS,避免無用的 HTML / CSS 解析。
CSS - render blocking:當執行 CSS 時,HTML可以繼續被 parsing,但 render tree 的建構會被暫停。因為 render tree 有 DOM 和 CSSDOM 這兩個來源,瀏覽器會等待整個 CSS file 的 CSSDOM 解析完後,再產生 render tree。
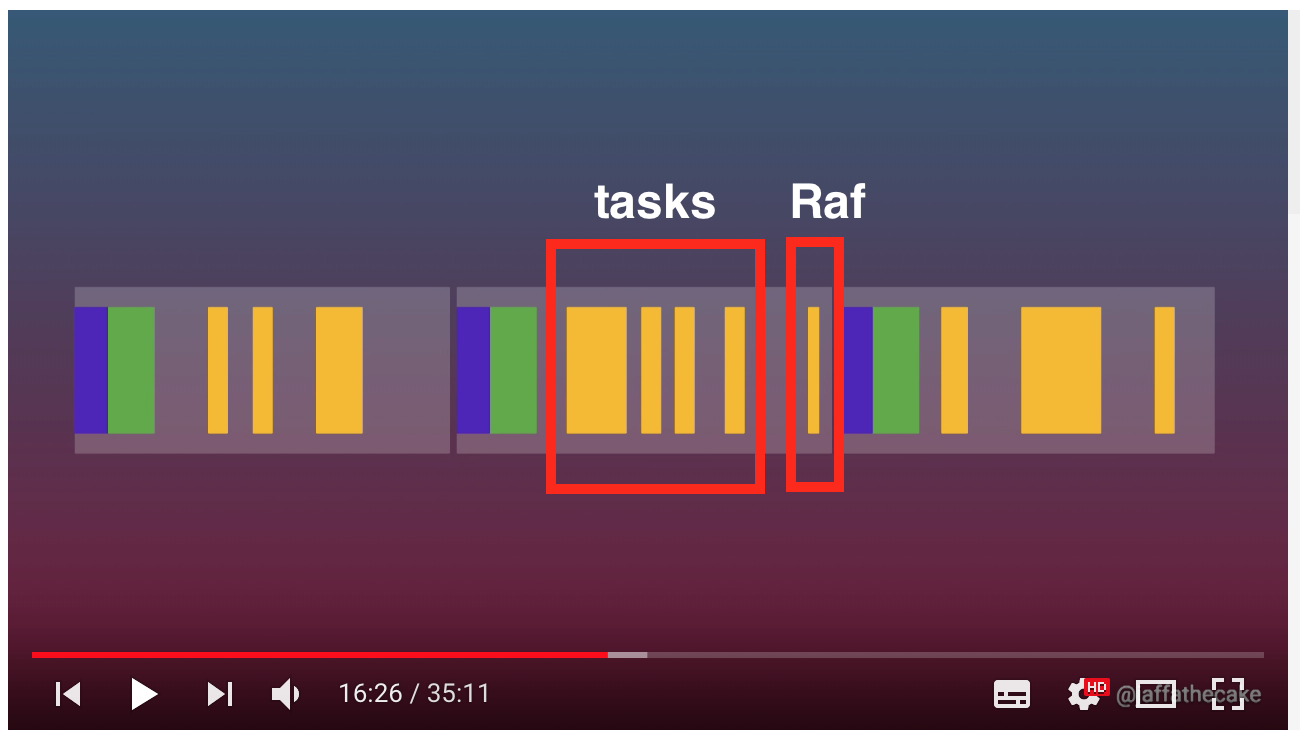
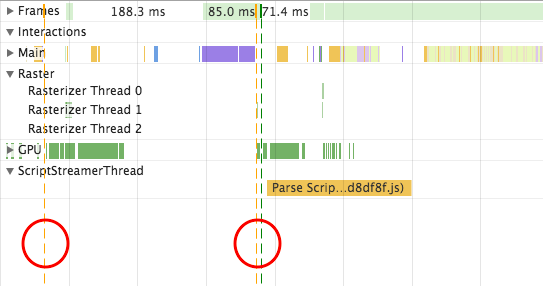
以瀏覽器的角度,會希望越快讓使用者看到畫面越好,所以它不會全部的 HTML 解析完才 Paint 頁面,而是將任務切成很多塊,解析完一部分就直接渲染到頁面,導致網頁擁有漸進出現的視覺效果。
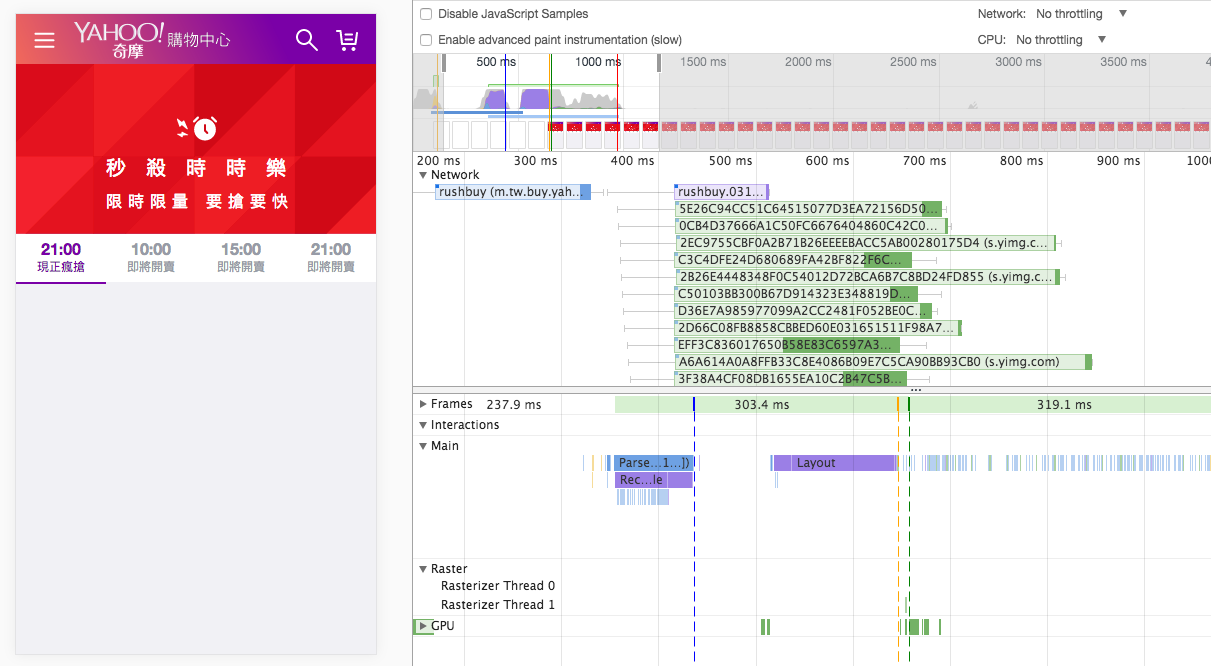
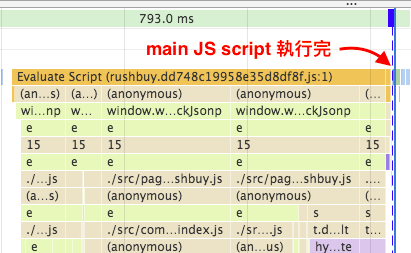
時時樂頁面觀察
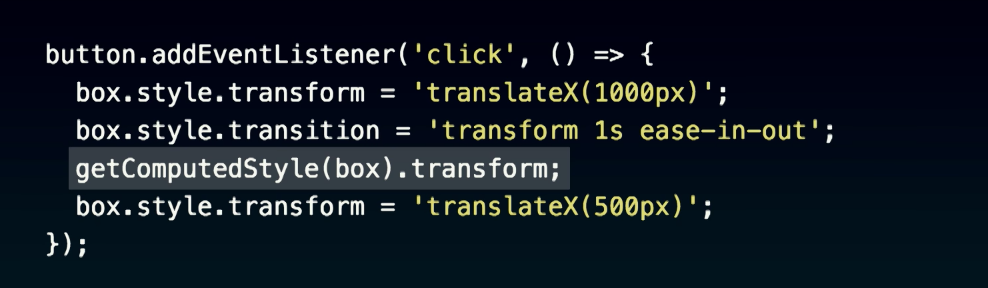
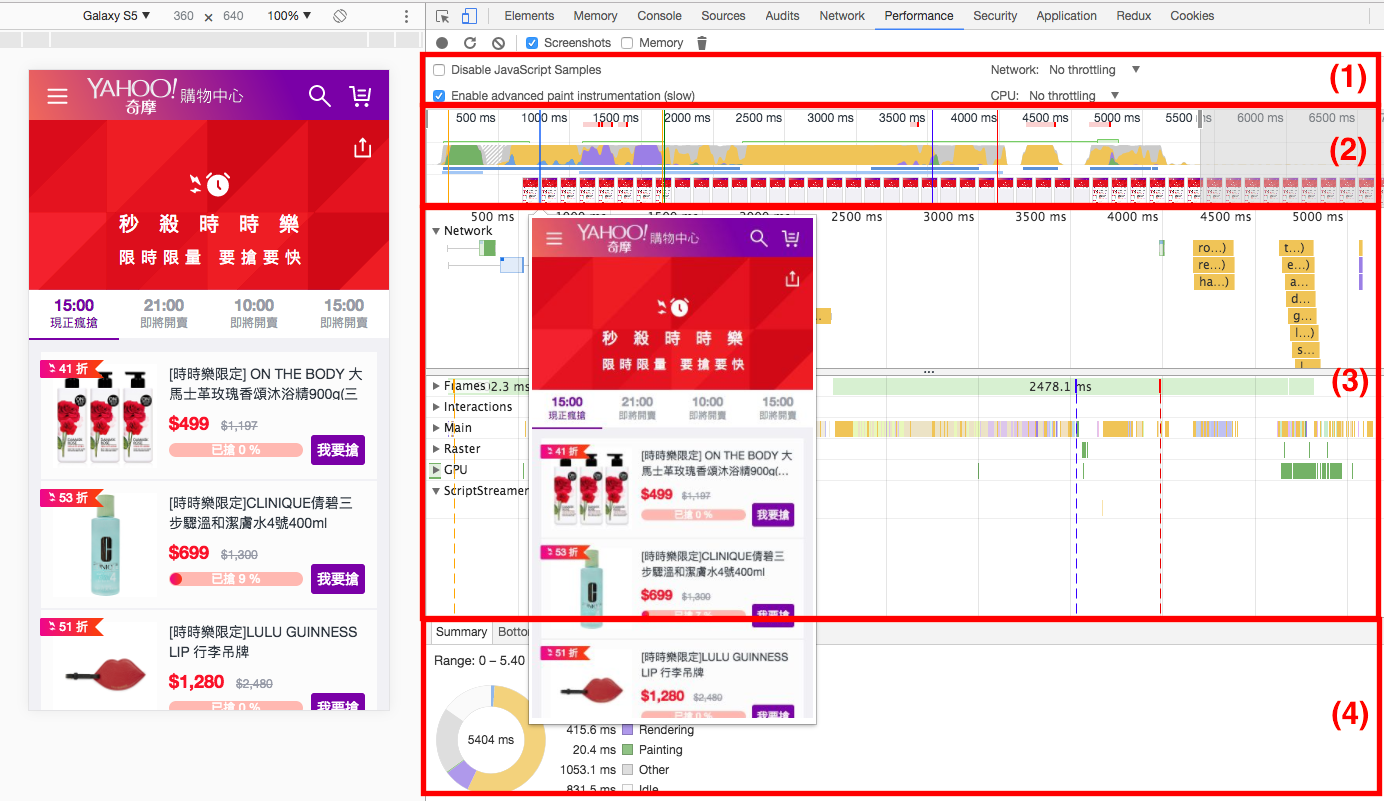
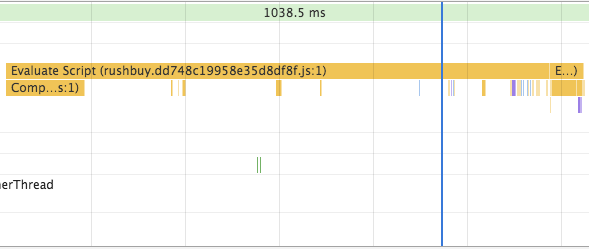
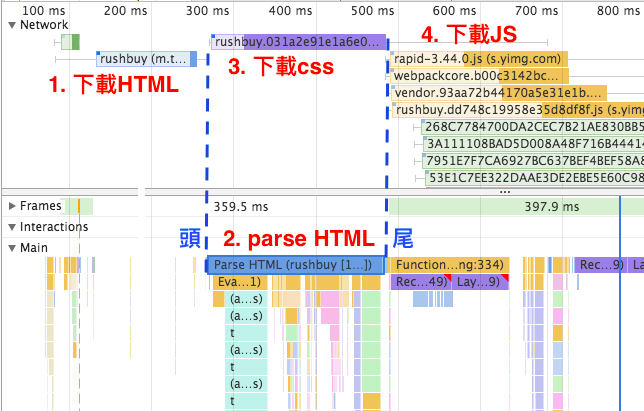
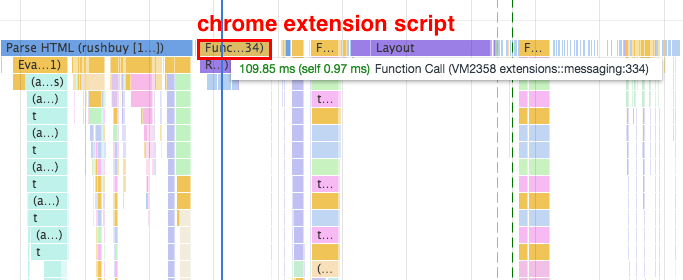
有了以上觀念後,我們再來對照看看真實網頁的頁面渲染過程。開啟 Dev Tool 後,建議禁用所有 chrome extension 來避免分析干擾,由下圖的 Main section 可以觀察到,chrome extension script 也會造成 parser blocking,安裝Disable Extensions Temporarily可以方便我們禁用 chrome 插件。
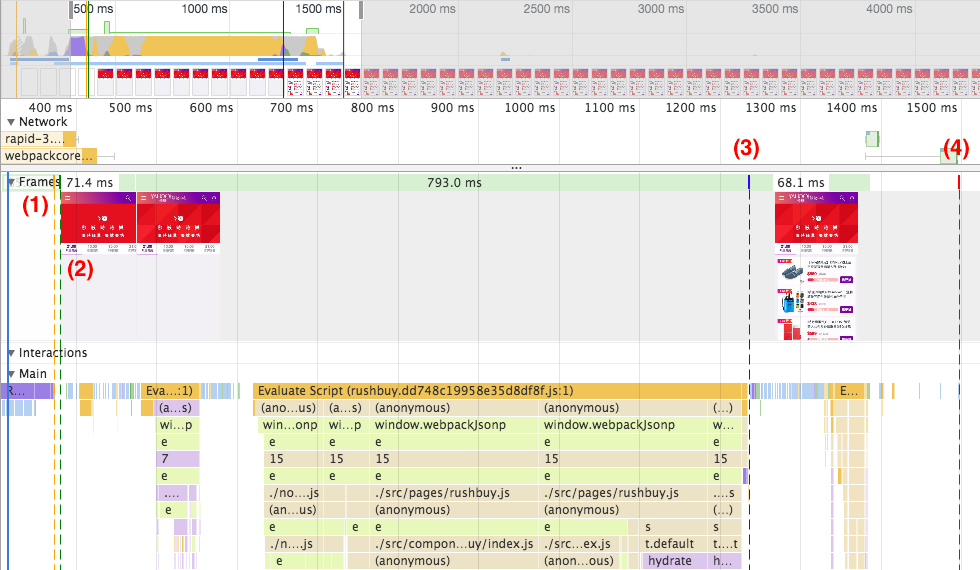
在開測之前,先簡單介紹這個頁面的架構。本頁面是採用 React + Redux 的 isomorphic app 架構,畫面大部分的 HTML 標籤和 store 的部分資料已經包含在 HTTP response 中 (server side render),isomorphic app 的好處有避免敏感的 API endpoint 露出、讓 First Meaning Paint (FMP) 的時間快一點、SEO 較好 (給搜尋引擎較多 HTML 資訊) 等…
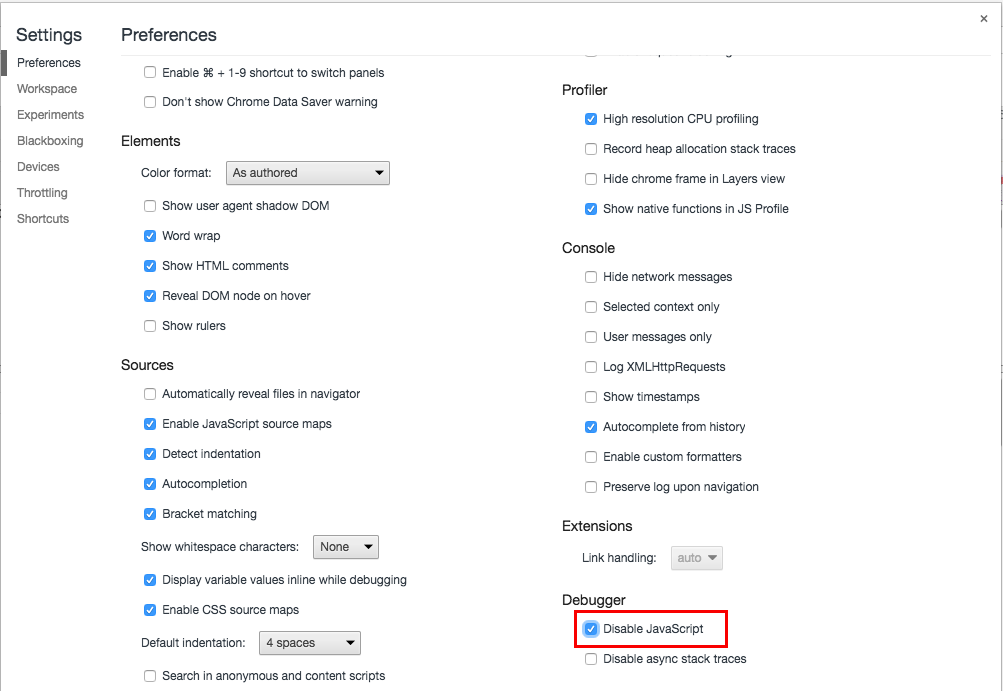
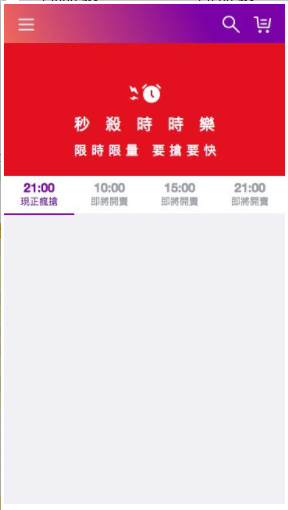
大部分的 server side render 都會包含到 hero element (重點元件) 的內容,我們可以藉由勾選 disable javascript 來禁用本頁面的 JS,觀察 server side render 出來的 HTML 畫面長什麼樣子。
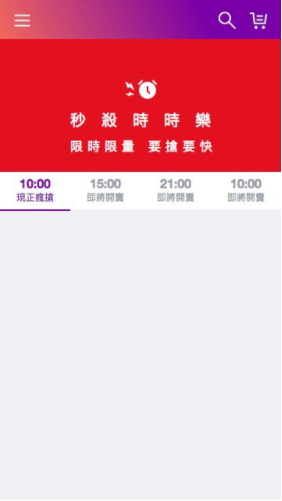
下圖是沒有執行任何 JS 的時時樂頁面,由此我們可以知道標籤列以下的內容是 client side render;標籤列以上的大 Banner 可能就是本頁的 hero element。
如果妳嘗試點擊標籤列會發現根本無法切換標籤,這是因為 client side 的 JS 被拔掉導致 onClick handler 沒有被附加到 HTML 元件上,使用者因此無法和元件互動,只能閱讀頁面內容。所以我們會建議在撰寫 React Component 時多使用原生 HTML tag 擁有的功能,像是要做 hyperlink 就要用 <a href=”” > 而不是 <div onClick={this.clickHandler} >,讓使用者在等待 client side JS 跑完之前,能和頁面做一些簡單互動。
目前只有 HTML templates 已經成為標準,其他三個仍在草稿階段,列為標準的好處是瀏覽器會接著跟進實作,如果未來做到全面支援,所有人就能直接利用原生的 BOM API 開發 web component,不只網頁效率倍增 (ex. Alex Russell 在 Chrome Dev Summit 2016 提到,如果使用 Framework,網頁渲染效率就會受限於框架本身,Framework是個對開發者方便,但將效率成本加築在終端使用者上的東西…),也解決前端框架無法相容的問題了。要撰寫自己的 web component,重點在活用 custom elements API 和 shadow DOM,因為目前各大瀏覽器的支援度仍不足,在開發前要先引入 web component polyfill
adoptedCallback:整個 custom element 被人用 document.adoptNode(el) 呼叫時觸發。
以下是自定義元件範例的JS部分,這裡的 this 代表該 custom element 本身,其擁有的 DOM API (ex. hasAttribute) 都可以使用。下方範例裡的 Example class 繼承了 HTMLElement class,開放 ex 屬性給使用者做 getter/setter JS 設置,並監控其屬性變更,我們可以藉由 console.log 觀察剛剛提到的生命週期。
classExampleextendsHTMLElement{// A getter/setter for an open property.getex(){returnthis.getAttribute("ex");}setex(val){// Reflect the value of the open property as an HTML attribute.if(val){console.log("set ex attritube: "+val);this.setAttribute('ex',val);}else{this.removeAttribute('ex');}}setid(val){// Reflect the value of the open property as an HTML attribute.if(val){console.log("set id attritube:"+val);this.setAttribute("id",val);}else{this.removeAttribute("id");}}staticgetobservedAttributes(){return["ex"];}attributeChangedCallback(name,oldValue,newValue){consthasValue=newValue!==null;switch(name){case"ex":console.log("the ex is changed on "+oldValue+" to "+newValue);break;}}constructor(){super();// always call super() first in constructor.console.log("In constructor");}}customElements.define('my-example',Example);// set attribute by JSdocument.getElementsByTagName("my-example")[0].ex="setByJS"// set id but not trigger attributeChangedCallbackdocument.getElementsByTagName("my-example")[0].id="example"
在 HTML 插入剛剛定義的 custom Tag:
<div><my-exampleex="HAHA"></my-example></div>
我們可以觀察到 console 輸出為:
HTML 解析器解析到 my-example 標籤後,會先運行 constructor,再觸發 attributeChangedCallback,設定 ex 屬性為 HAHA,接著我在 JS 呼叫 set ex method 將 ex 設定為 setByJS,一樣也觸發了 attributeChangedCallback! 接著我們再用 JS 呼叫 set id method,設定屬性 id 為 example,但這次沒有觸發 attributeChangedCallback,因為只有 observedAttributes 所列的屬性被改變,才會觸發 attributeChangedCallback。
有了custom element 所提供的 DOM API,我們就能透過自定義屬性和添加 Event Listener,編寫 custom element 與終端使用者互動的邏輯,再配合 shadow dom 的封裝特性,做出華麗的外觀與變化。如何配合運用會在下面繼續說明。
Shadow Dom 封裝元件內部的 HTML DOM/CSS,使其不受元件外面的環境影響,且因為外部的 CSS 無法直接修改到 shadow dom 的 CSS 內容,故 Shadow Dom 的 CSS class 命名可以和外部的 CSS class 撞名。目前的 HTML5 元件像是 <video>, <audio>, 各種 <input> 等等,都是 Shadow Dom 應用的產物。
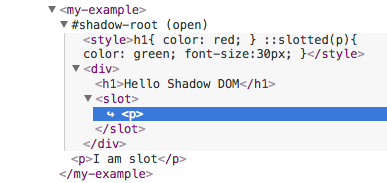
要加 Shadow Dom,直接在 custom element class 的 constructor 裡用 this.attachShadow() 綁定 Shadow Dom Tree,官方建議不要用關閉模式 { mode: ‘closed’ } 創建 Shadow Dom,因為它會讓使用此 custom element 的開發者不能透過任何方式修改該 Shadow Dom 的 style 樣式,使該 custom element 的修改彈性變很低。綁定後,用 innerHTML 直接插入 dom 和 style 字串,之後的撰寫方式都和編寫普通的 HTML/CSS 相同,標籤 <slot> 代表插入 custom element 的 child element 位置所在,我們能用 ::slotted(css slector) 來裝飾該 child element。
以下是JS的範例,style 說如果 child element 為 p,則字的大小設 30px、顏色設為綠色
classExampleextendsHTMLElement{constructor(){super();// always call super() first in constructor.letshadowRoot=this.attachShadow({mode:'open'});shadowRoot.innerHTML='<style>h1{ color: red; } ::slotted(p){ color: green; font-size:30px; }</style><div><h1>Hello Shadow DOM</h1><slot></slot></div>';}}customElements.define('my-example',Example);
Html範例,my-example標籤內有子元件 <p>I am slot</p>:
<div><my-example><p>I am slot</p></my-example></div>
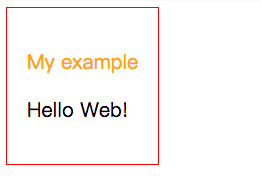
以下是呈現出來的畫面,我們可以看到子元件在紅色的 Hello Shadow DOM 後面,且被裝飾成綠色。
開 chrome console 可以觀察到 render dom tree 的 my-example 標籤下有 #shadow-root,內能觀察到被渲染的 shadow dom tree,外面的 CSS 是無法修改到此區域的 style
使用 HTML template 先定義好 Shadow Dom 的 HTML 結構和 style,再在 custom element 的 constructor 內複製 template 的內容節點到 shadow root。這種做法讓 custom element 的 shadow dom tree 更易讀也更好維護。
var_selector=document.querySelector;_selector('#search-button').addEventListener('click',function(event){event.preventDefault();letssn=_selector('#student-ssn').value;getRemoteData(`/students/${ssn}`,function(info){_selector('#student-info').innerHTML=info;_selector('#student-info').addEventListener('mouseover',function(){getRemoteData(`/students/${info.ssn}/grades`,function(grades){// ... process list of grades for this student});});})});}});
為了讓程式更可讀,我們利用 javascript 的 function 是 first class citizen 的特性,將這些 callback 命名成一個個易解讀的變數並分離出來,這種做法叫做 continuation-passing style (CPS)。像上面的例子,可以被重構成如下。
var_selector=document.querySelector;_selector('#search-button').addEventListener('click',getStudentSNN);vargetStudentSNN=function(event){event.preventDefault();letssn=_selector('#student-ssn').value;getRemoteData(`/students/${ssn}`,showInfoAndFindStudentGrade(info)).fail(showError);}};varshowError=function(){console.log('Error occurred!');};varshowInfoAndFindStudentGrade=function(info){_selector('#student-info').innerHTML=info;_selector('#student-info').addEventListener('mouseover',function(){getRemoteData(`/students/${info.ssn}/grades`,function(grades){// ... process list of grades for this student});});};
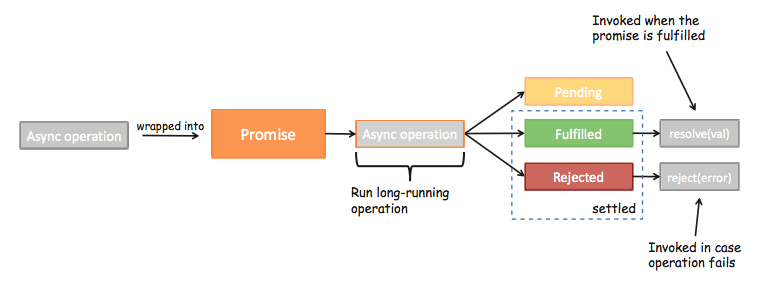
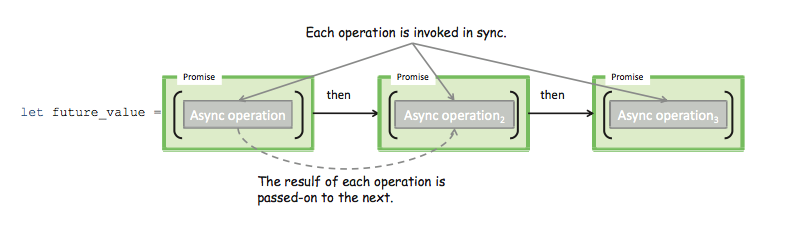
varfetchData=newPromise(function(resolve,reject){// fetch data async or run long-running computation$.get(url,function(result){if(<success>){resolve(result);// successful calllback}else{reject(newError('Error performing this operation!'));}});});

![[DevOps]鳳凰計畫](http://mis101bird.github.io/images/chase.png)
![[影片推薦]瀏覽器中Javascript的運作機制](http://mis101bird.github.io/images/sydney1.jpg)



![[Performance]瀏覽器運作與效能指標評估](http://mis101bird.github.io/images/hotels.jpg)
![[Web Component v1]JS Framework 以外的另一條道路](http://mis101bird.github.io/images/winter.jpg)


![[Javascript]非同步的救星Promise](http://mis101bird.github.io/images/leak.png)